A fleet of agents that ships code to my repos
For the last few months I've been running a fleet of AI agents that ships code into my repositories. Not "AI-assisted coding" — the agents actually open the pull requests. I review and merge. The system runs on a 15-minute scan loop, dispatches work to specialist agents, and has produced something like sixty merged PRs across six repos.
It's mostly boring, which is the goal. This post is the demo: what it looks like, why the three design choices matter, and where the human (that would be me) stays in the loop on purpose.
Why I built this
Two reasons. The shallow one: I wanted to ship features to my own products (a books app, a personal-finance project, a mental-health tool) faster than I could write everything by hand, and I wanted to see what production-grade agent tooling actually feels like to live with.
The deeper one: AI enablement is going to be one of the most consequential lines of work for the next several years, and I want to be useful to other companies that want to do this — not as a person reading the same blog posts they could read themselves, but as someone who's run the system. Built it. Watched it fail at 2 AM. Argued with it. Iterated on the guardrails. There's a credibility you can only earn by having lived inside the thing you're advising on, and that's the credibility this build is meant to earn.
So this is both an internal R&D project and a portfolio. Everything below is real, deployed, in daily use. The code is in private repos but the architecture is generic and the design decisions are documented as they happened.
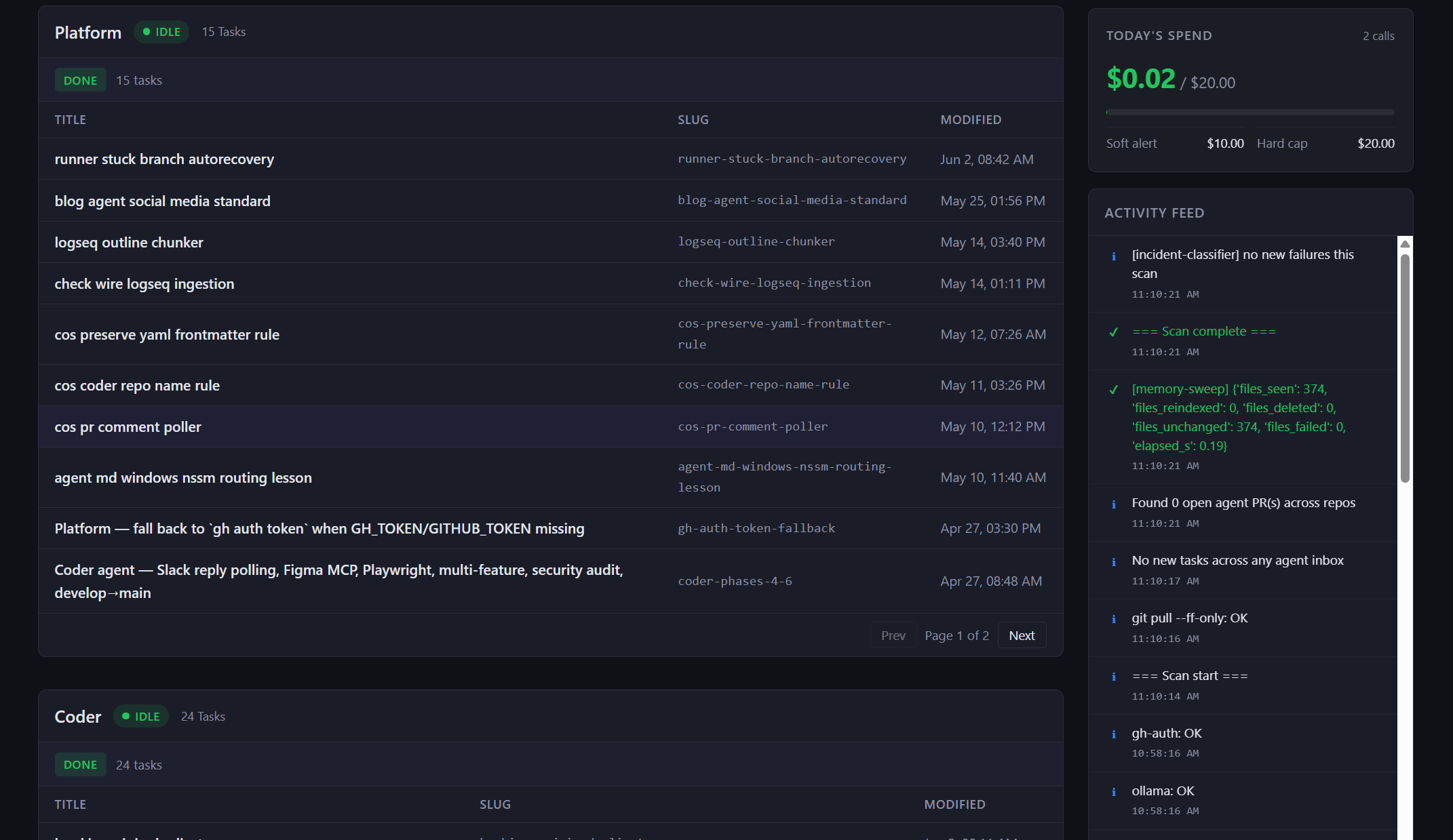
cost.db.The system in one paragraph
I DM a chief-of-staff agent ("Vera" — she came up with her name and even gendered herself!) in Slack with a high-level goal. She proposes a task by opening a PR that adds one markdown file to an inbox folder in my agent platform repo. I review and merge the task proposal. On the next scan, a specialist agent picks the file up, does the work in a target repo, opens an implementation PR. I review and merge. The source file moves to done/. The next ask starts the same way.
Everything else — branching, commits, force-push-with-lease for conflict resolution, draft-vs-ready-for-review, log collection, daily spend tracking, retries on transient failures — is plumbing.
The cast
Five agents, each with a deliberately narrow job description:
- Vera (chief of staff). Talks to me in Slack. Proposes tasks. Cannot write code. Cannot merge PRs. Her only write tools are: create a task-proposal PR, post a Slack reply, leave a comment on her own PR. She runs Sonnet 4.6 because her job is routing, not generation.
- Coder agent. Builds code changes in any target repo. Reads files, edits them, runs tests, opens a PR. Cannot modify the agent platform itself. Cannot merge its own PRs. Has a maximum revision-round count (5) so it can't loop forever if it can't satisfy a review comment.
- Research agent. Drafts markdown documents only — plans, design docs, deep code analysis. Cannot ship production code. Output goes to a separate knowledge repo where I can read and decide what to act on.
- Blog agent. Drafts blog posts plus social-media variants. Markdown only. Same constraint as research.
- Platform agent. Edits the agent platform itself. Highest blast radius. Requires an explicit
platform_task: trueflag in the task file's frontmatter — otherwise the coder agent runs and refuses. Risky changes (anything touching the runner, the auth layer, the cos daemon) require a Slack approval reply before the commit lands.
There's also a monitor that runs every 5 minutes checking that the platform itself hasn't wedged. It auto-recovers from most failure modes (orphaned processes, stale PID files, a stuck CoS daemon) and DMs me when it can't.
Below all of this, an operator-side coding tool — currently OpenCode, replacing Claude Code — handles the human-driven work: investigations, debugging, the kind of session where I want to drive the agent directly. Same OpenRouter account, same dashboard, same daily spend cap.
Why vendor agnosticism actually matters
The agents don't talk to Anthropic. Or Google. Or any specific model provider. They talk to OpenRouter, which proxies to whichever model the task picked.
This is a single environment variable away. The claude_agent_sdk (the Python SDK that powers Claude Code) speaks the Anthropic API protocol. OpenRouter exposes the same protocol at https://openrouter.ai/api. Setting ANTHROPIC_BASE_URL to point there — before the SDK loads — silently redirects every request without any code change to the agent itself.
I learned how much this matters on May 14. Anthropic announced a billing split: programmatic SDK usage on subscription plans would move to API-priced credit pools starting June 15. Every other company building agents on claude_agent_sdk had to plan a migration, decide whether to absorb the cost, or rebuild on a different SDK.
I had to do nothing. The Stonepath stack has been routing through OpenRouter the entire time. Anthropic never sees the request. The "Agent SDK pool" doesn't apply.
That's the vendor-agnosticism story in one sentence: structural insulation from any single provider's pricing or policy decisions. Whether they raise prices, change billing, deprecate a model, or have a bad week — my system doesn't notice.
The same insulation works for capability. If Gemini 3 ships a coding model that beats Opus on real tasks tomorrow, I change a string in config.yaml and the next coder run is on Gemini. No infrastructure work. No SDK swap. The agents don't care.
This isn't theoretical optionality. I already use it: orchestration runs on Sonnet (cheap and good enough for routing decisions), code generation runs on Opus 4.7 (worth the price for serious refactors), low-priority sweeps run on cheaper models that I'd never trust to ship code unsupervised but that are fine for triage. The same OpenRouter account, the same dashboard, one daily cap.
Why not just use OpenClaw or Hermes
A reasonable question. Both are popular third-party agent frameworks that wrap Claude (and other models) for autonomous coding work. They have real users, real momentum, and they would have saved me weeks of plumbing time. I deliberately didn't use them.
The reason is trust surface. A third-party agent framework sits in the middle of your most sensitive systems: your repositories, your GitHub personal access tokens, your environment variables, your local filesystem. Anything the framework can read, the framework's authors can theoretically see. Anything the framework can write, the framework's authors can theoretically alter. You're not just using a model — you're hiring a coordinator that has your dev environment's keys.
For my personal projects, that calculus is borderline. For client work, it's a non-starter. If I'm going to advise a company on running autonomous agents inside their development environment, I need to be able to point at every layer of the stack and explain who can see what. "We use OpenClaw" doesn't answer that question. "We use Anthropic's official SDK, route LLM calls through OpenRouter under our own account, and the orchestration code is in our own repo where we can audit every tool call" does.
Specifically, here's what I wanted to control myself and what wrappers tend to abstract:
- Tool allowlists. I want to decide what tools the agent gets, per-task. Many frameworks ship a fixed tool set that's hard to constrain.
- Telemetry path. I want to know exactly what data leaves my machine and where it goes. A wrapper that "anonymizes" for analytics is a wrapper that's still seeing the raw data first.
- Budget enforcement. I wanted hard caps on daily spend with an override path I controlled (Slack reply to my own bot). External budget UIs are someone else's circuit breaker.
- Audit log. Every LLM call lands in a SQLite ledger I own. Every PR is in git. Every Slack thread is in my workspace. The system is its own audit trail.
- Vendor independence at the orchestration layer. I'm already insulated from any single model provider via OpenRouter. Building on a wrapper would re-introduce a single-vendor dependency at a level above the model.
This is also the substance behind Anthropic's May 14 billing change. Their stated reason was "subscription arbitrage" — third-party agent frameworks running long-cycle Opus jobs on $20–$200 subscriptions and burning through hundreds of dollars of tokens that the wrapper, not the user, was effectively pocketing the value of. From Anthropic's side, that's a structural cost problem. From the user's side, it's the same trust-surface question in a different costume: do you actually know who's running your model?
None of this is meant as a swipe at OpenClaw, Hermes, or anyone else. They're real products solving real problems for users whose threat model accepts the trade. Mine doesn't, and a client's almost certainly wouldn't.
How memory works
Agents that can't remember are chatbots in a costume. Memory is what lets Vera not ask "what are we working on?" every morning, what lets the coder reuse conventions established in past PRs, and what makes the cost cap actually mean "today's spend" instead of "this session's spend."
There are three memory tiers in the system, each with different update mechanics:
- Hot — conversation state. Vera's Slack threads are persisted to
tasks/source/cos/state/<thread_ts>.jsonafter every turn. When you reply to a thread three days later, Vera reads the file and resumes with full context. Files older than a configurable window get archived but never deleted; the canonical conversation lives in Slack. - Warm — indexed knowledge. Markdown corpus (knowledge repo, blog posts, prior research outputs, agent task files) is embedded into a SQLite index at
memory/index.db. A file-watcher daemon re-embeds on change with a sha256 short-circuit, so only truly-changed files do real work. The agents query this index for grounded retrieval — when Vera answers a question, she's pulling cited passages from the corpus, not relying on the model's training data. - Cold — git itself. Every task file, every implementation PR, every agent commit is in git history with a real author email, a timestamp, and a reviewable diff. Six months from now, the question "why did we build it this way?" is answered by
git logandgit blame, not by hoping the model remembers.
A fourth memory surface lives in memory/cost.db — the daily spend ledger and any active budget overrides. It's small but load-bearing: every LLM call pre-checks against today's total before firing, and the override mechanism (a Slack reply: "allow $X more") writes a row here. The override expires at midnight local time unless extended.
The interesting design property is that the agents share memory, but each respects its scope. Vera can read the indexed knowledge but only writes conversation state. The coder reads the indexed knowledge but writes only inside its workspace. The platform agent reads everything but writes only via PRs. Memory access is constrained by the same allowlist mechanism that constrains tool use.
There's also explicit short-term memory for me — a personal memory file the operator-side coding agent (currently OpenCode) maintains across sessions. It's how the agent remembers feedback like "always use single quotes in this repo" or "prefer one bundled PR over incremental ones for platform work." This is the kind of memory that a chatbot can't have because it lasts beyond a session.
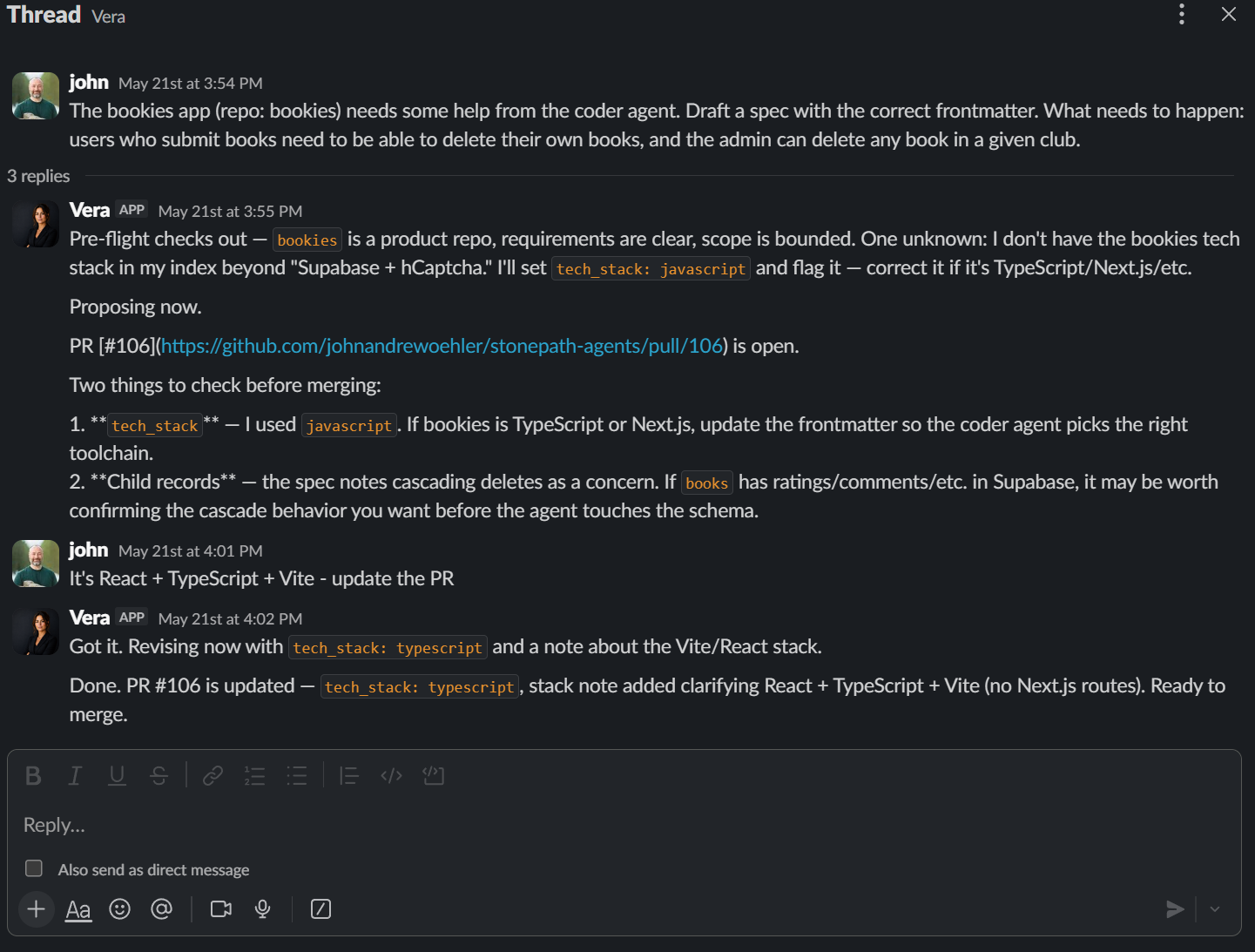
GitHub is the guardrail
The single most important architectural decision was making every change a PR.
Nothing the agents do bypasses code review. Vera doesn't push to main. The coder doesn't push to main. The platform agent doesn't push to main. They push to branches, open PRs against main (or develop, where the target repo uses one), and stop. I merge or I don't.
This sounds obvious but it has consequences:
- Every action is reviewable in a familiar interface. I look at diffs, I leave review comments, I merge. I'm not learning a new "agent operations" tool. I'm reading PRs.
- Failed agent work is preserved. Tasks that error out get moved to a
failed/folder. The task file, the full log, and the partially-completed branch all sit there for me to inspect. Nothing gets silently discarded. - Revision is normal. If I leave a comment on a PR asking for changes, the agent reads it on the next scan and pushes a revision commit. Up to five rounds, then the agent flags itself stuck and waits for a human. The PR conversation is the source of truth.
- The platform updates itself the same way. When I want to add a new feature to the agent system, the platform agent opens a PR against the platform repo. I review it like any other PR. The system bootstraps itself through the same review mechanism it uses to ship product code.
The two-merge pattern — merge the task proposal, then merge the implementation — is friction by design. It gives me two distinct checkpoints to bail out before code lands. The first merge says "yes, work on this." The second says "yes, I accept this implementation."
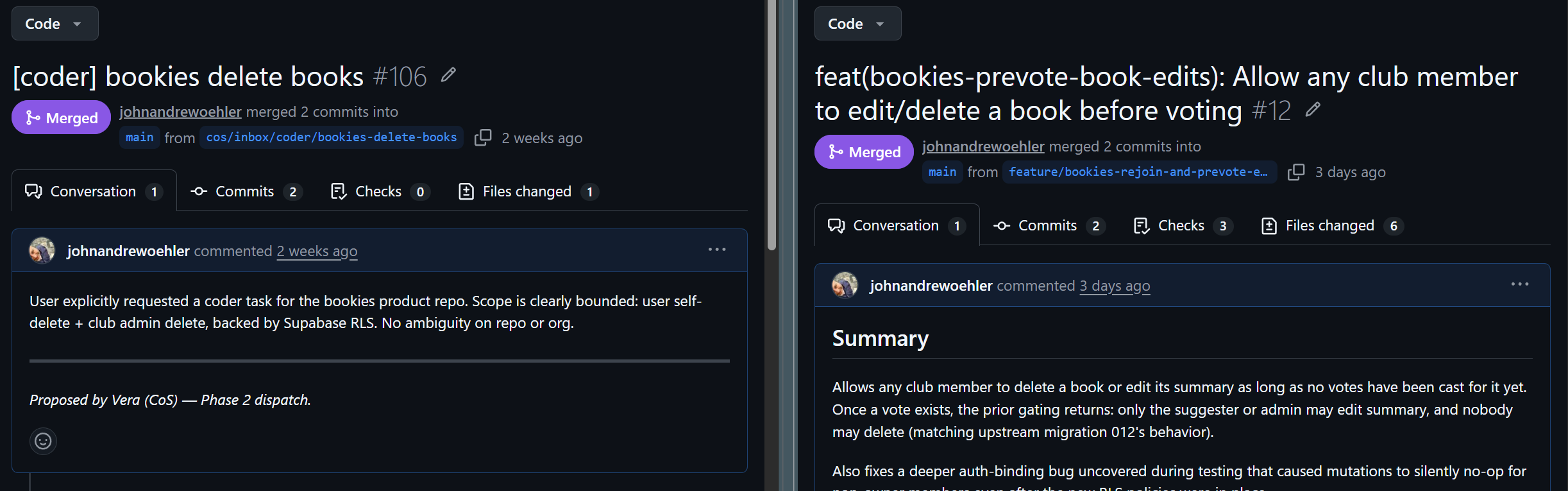
tasks/source/coder/inbox/ (left), and the coder agent's resulting implementation PR with real code changes (right).There's a secondary benefit that took me a while to appreciate: GitHub's tooling for collaboration is excellent and I get it for free. PR comments, draft mode, force-with-lease, squash merges, branch protection rules — all of that just works because I'm using GitHub. I didn't build any of it. The platform integrates by using gh and respecting the conventions.
What the agents explicitly can't do
The hardest part of building a useful agent fleet wasn't getting the agents to do things. It was getting them to not do things they shouldn't.
Each agent has explicit, enforced limits:
- Tool allowlists. The coder agent can call
Read,Edit,Write,Glob,Grep, andBash. That's it. No network calls, no MCP servers it didn't ask for, no arbitrary tool invocation. Same constraint on every other SDK-driven agent. - Permission modes. The coder runs in
acceptEditsmode — file edits go through automatically, but anything that would touch the system outside the workspace requires explicit permission. Acan_use_toolcallback gates the marginal cases. - Workspace isolation. Each agent run gets a fresh clone of the target repo in a workspace directory.
git reset --hard origin/mainbefore every run guarantees deterministic state. If the agent corrupts the workspace, the next run wipes it. - Budget enforcement. Every LLM call goes through a cost-monitor that tracks daily spend. If today's spend plus the estimated cost of the next call would exceed the daily cap, the call refuses. Override is a Slack reply (
allow $X more) — no code change. - Scan lock. Only one scan can run at a time. If a long-running research task hasn't finished when the 15-minute timer fires again, the second scan logs the lock and exits cleanly. No concurrent inbox processing.
- No self-merging. No agent — not even the platform agent — can merge its own PR. Every PR requires a human to click the green button.
- No production deployment. None of these agents touch production systems. They open PRs. CI/CD picks up from there, governed by the same release process I'd use for any other PR.
The last one is structural. The agents live inside the development surface — code, PRs, task files, Slack threads. They don't reach into running systems. Anything that affects users requires a human-triggered deploy.
A real example
Yesterday I dispatched a coder task and it didn't run. I merged the task-proposal PR, the next 15-minute scan should have picked it up, and three scans later the runner was still logging "No new tasks across any agent inbox." Something was wrong.
I used OpenCode — the operator-side coding agent that drives my own investigations — to figure it out. The prompt was a paragraph: check gh for the PR, check the runner log around the merge time, check the cost ledger for a coder run, check the target repo for an implementation PR, report what's stuck and why.
OpenCode worked through the question for about three minutes. It pulled the PR metadata, found the task file at tasks/source/coder/inbox/<slug>.md, confirmed it never appeared in the runner's working tree, and traced the cause: every scan was logging git pull --ff-only: non-zero (1) ... no such ref was fetched 'doc/runbook-opencode-track-a'. The runner's local checkout had been left on a feature branch from an earlier PR. That branch had been squash-merged on origin and the remote ref deleted, which made git pull --ff-only fail every scan. The runner never advanced to main, so it never saw the new task.
The diagnosis was clean, the evidence was specific (commit hashes, log timestamps, cost-ledger rows), and the proposed root cause was right. I'd been bitten by the same bug two days earlier on a different branch and dismissed it as a one-off. OpenCode saw it as a pattern.
The fix was a small change to the runner: at the top of every scan, before the pull, detect "HEAD is on a non-protected branch whose upstream is [gone]" and auto-check-out main when the working tree is clean. Refuse to auto-switch with uncommitted work — that path would risk stomping in-progress changes. Add six unit tests covering the happy path and every safety guard. Open a PR.
One investigation, one fix, two PRs across two repos, all reviewable, all merged the same morning. The system caught and corrected a systemic flaw in itself through the same review mechanism it uses to ship product code.
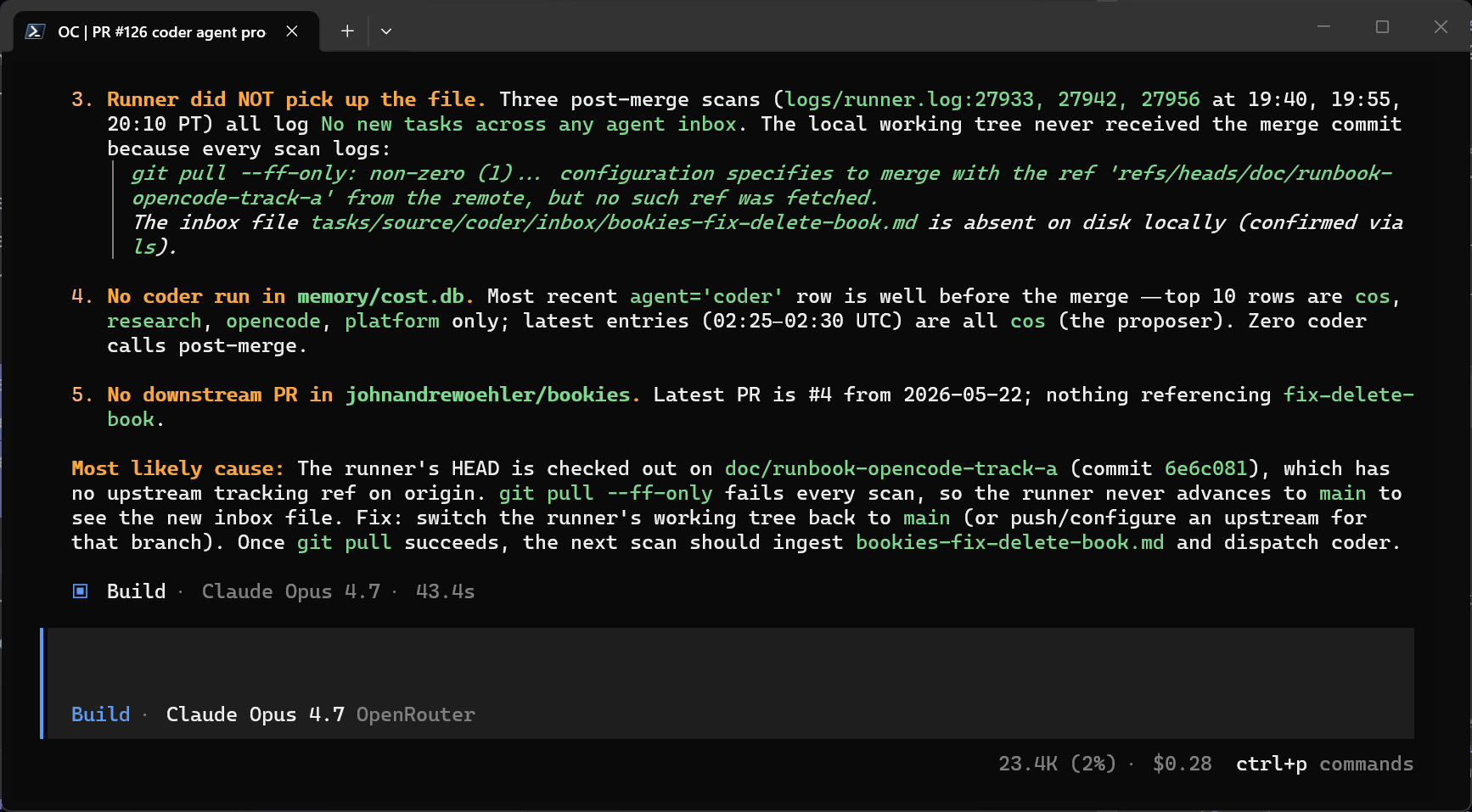
git pull --ff-only failed every scan and it never advanced to main to see the new inbox task.This is the system working as intended. The agent did the diagnosis and the implementation. The PRs documented the work. I made the merge decisions. The next scan picked up the fix and the runner caught itself up to main on its own.
What's not autonomous
The human stays in the loop for:
- The brief. Vera doesn't decide what to work on. I tell her.
- Both merges. Task proposal and implementation. Every change.
- Risky platform changes. Anything touching the runner, auth, or the cos daemon requires a Slack approval.
- Production deploys. No agent ships to production. PRs land; deploy happens through normal release processes.
- Budget overrides. When an agent hits the daily spend cap, the override is a Slack reply, not a config change.
- Anything weird. When the monitor catches a failure it can't auto-recover, it DMs me. When the auto-remediation classifier sees a destructive fix (e.g., a force-push), it queues it for Slack approval.
This isn't lack of trust — it's correct division of labor. The agents are very good at the well-bounded mechanical work: branching, editing, testing, opening PRs, replying to review comments. They're not asked to make judgment calls about strategy, priority, or risk. I do that.
What's next
The current focus is operator-side tooling. The agentic stack is on OpenRouter; the tool I use to drive my own investigations was on Anthropic direct. Anthropic's billing change made that lopsided. So I'm migrating to OpenCode + OpenRouter for the operator side too, which would put the entire system — autonomous agents and human-driven work — on the same billing surface and the same set of agnostic provider choices.
After that, the next architectural piece is better phase decomposition for big tasks. The platform agent can already split large feature work into multi-step plans, but I want each step to land as its own PR rather than one giant implementation PR. Smaller diffs are easier to review and easier to revert.
Closing
The pitch isn't that AI agents are magic. The pitch is that AI agents are useful when you treat them like a junior team member: give them tools they can use, give them limits they can't escape, and review their work before it ships. Vendor agnosticism is the insurance policy that lets you trust the system. GitHub is the workflow that makes the work reviewable. Explicit agent limits are the safety net that keeps the system from doing something stupid at 3 AM.
The hard part isn't the model. The hard part is the plumbing. I'd build it again exactly the same way.
If your company is thinking about deploying autonomous agents inside its development workflow — production code, internal tools, anything where the agent has a foot on real systems — and you'd like to talk through what these design decisions look like applied to your context, the contact link is in the footer. I'm not building enablement consulting as a primary business yet, but I'm taking a small number of conversations to learn what other teams are running into.